

|
|
<- Linux - Copertina - XFSTT -> |
|
Articolo
Il filesystem Extended 2 (ext2) è attualmente quello più diffuso in Linux, quello che viene usato normalmente per formattare le partizioni in cui viene installato il sistema. Le principale caratteristiche del filesystem ext2 possono essere riassunte nella seguente tabella:
| Dimensione massima del filesystem | 4 TB |
| Dimensione massima dei files | 2 GB |
| Lunghezza massima dei nomi | 255 caratteri |
| Fast symbolic links | Si |
| Supporta ctime, mtime e atime | Si |
| Spazio riservato per root | Si |
| Attributi estesi dei files | Si |
| Parametri modificabili | Si |
Come tutti i filesystem unix anche l'ext2 è organizzato in una struttura ben progettata comprendente super_block, inodes, directory e files. Vedremo quindi in dettaglio come sono strutturati i singoli componenti del filesystem ext2, d'ora in poi chiamato semplicemente fs, e quali sono i vantaggi di tale organizzazione.
Lo spazio all'interno di un filesystem unix è organizzato logicamente come un array lineare di blocchi di dimensioni uguali. La dimensione del blocco logico è indipendente dalla dimensione dei blocchi del dispositivo fisico ed è di solito di 1024 bytes, ma può essere fissata anche in 2048 o 4096 bytes. Viceversa il blocco fisico di un normale harddisk è di 512 bytes, quindi un blocco logico occupa di solito 2 blocchi fisici.
In unix ogni filesystem ext2 è descritto da un blocco particolare detto super_block che è memorizzato in posizione fissa all'inizio del fs stesso e ne descrive le caratteristiche, dimensioni, struttura, stato ed altro ancora. Il super_block dell'ext2, chiamato ext2_super_block è descritto dalla seguente struttura:
/*
* Structure of the super block
*/
struct ext2_super_block {
__u32 s_inodes_count; /* Inodes count */
__u32 s_blocks_count; /* Blocks count */
__u32 s_r_blocks_count; /* Reserved blocks count */
__u32 s_free_blocks_count; /* Free blocks count */
__u32 s_free_inodes_count; /* Free inodes count */
__u32 s_first_data_block; /* First Data Block */
__u32 s_log_block_size; /* Block size */
__s32 s_log_frag_size; /* Fragment size */
__u32 s_blocks_per_group; /* # Blocks per group */
__u32 s_frags_per_group; /* # Fragments per group */
__u32 s_inodes_per_group; /* # Inodes per group */
__u32 s_mtime; /* Mount time */
__u32 s_wtime; /* Write time */
__u16 s_mnt_count; /* Mount count */
__s16 s_max_mnt_count; /* Maximal mount count */
__u16 s_magic; /* Magic signature */
__u16 s_state; /* File system state */
__u16 s_errors; /* Behaviour when detecting errors */
__u16 s_pad;
__u32 s_lastcheck; /* time of last check */
__u32 s_checkinterval; /* max. time between checks */
__u32 s_creator_os; /* OS */
__u32 s_rev_level; /* Revision level */
__u16 s_def_resuid; /* Default uid for reserved blocks */
__u16 s_def_resgid; /* Default gid for reserved blocks */
__u32 s_reserved[235]; /* Padding to the end of the block */
};
Si può notare che in esso sono contenuti tre tipi fondamentali di
informazioni:
I parametri modificabili possono invece venire cambiati dal superuser con il programma tune2fs, che permette di variare per esempio il numero massimo di volte che il fs può essere rimontato prima di forzare un fsck automatico, oppure il comportamento in caso di errore. Un interessante parametro modificabile è la percentuale di spazio che può essere riservata ad un utente privilegiato, normalmente root. Questo consente al sistema di continuare a disporre di spazio su disco anche quando il filesystem si riempie per l'uso smodato degli utenti.
Altre informazioni descrivono invece lo stato del filesystem e vengono aggiornate automaticamente man mano che il fs viene usato, per esempio il numero di blocchi liberi, lo stato (montato o meno), il numero di volte che esso è stato montato, ecc.
Una cosa che invece manca totalmente nel super_block è qualsiasi informazione sul tipo e sulla struttura fisica del device o della partizione in cui esso è ospitato. Il filesystem è infatti totalmente indipendente da queste informazioni, che viceversa sono importanti per poter accedere fisicamente alla partizione o al device. Il fs si basa infatti su un modello lineare della partizione sottostante che viene vista come un insieme di blocchi omogenei demandando al device driver tutte le operazioni necessarie per accedere ad un singolo blocco logico. Un fs può addirittura essere contenuto in un normale file contenuto in un altro filesystem e in questo caso parlere di tracce e cilindri sarebbe completamente privo di senso. Per questo motivo tali informazioni non sono memorizzate all'interno del fs. Per confronto vediamo invece cosa contiene un boot record del dos, l'analogo per certi versi del super_block di ext2:
struct msdos_boot_sector {
__s8 ignored[3]; /* Boot strap short or near jump */
__s8 system_id[8]; /* Name - can be used to special case
partition manager volumes */
__u8 sector_size[2]; /* bytes per logical sector */
__u8 cluster_size; /* sectors/cluster */
__u16 reserved; /* reserved sectors */
__u8 fats; /* number of FATs */
__u8 dir_entries[2]; /* root directory entries */
__u8 sectors[2]; /* number of sectors */
__u8 media; /* media code (unused) */
__u16 fat_length; /* sectors/FAT */
__u16 secs_track; /* sectors per track */
__u16 heads; /* number of heads */
__u32 hidden; /* hidden sectors (unused) */
__u32 total_sect; /* number of sectors (if sectors == 0) */
};
Si può vedere innanzitutto che ci sono molte meno informazioni che
nell'ext2,
per esempio manca un magic number che mi permetta di identificare
univocamente una partizione dos come tale o distinguere un fs msdos da uno
di tipo vfat.
Inoltre si può notare che nel boot record sono mescolate fra loro
informazioni sulla geometria del disco (media, heads, secs_track, ecc.),
informazioni sulla struttura del filesystem (cluster_size, fat_length, sectors,
ecc.) e perfino una variabile `ignored' che contiene nientemeno che
del codice eseguibile per 8086. Un bel casino, nel tipico stile Microsoft.
Tutto questo significa per esempio che non posso copiare brutalmente una partizione dos da un disco a un' altro se la geometria dei due dischi è diversa. Inoltre la mancanza di informazioni sullo stato del fs, la sua semplificazione e la scarsa ridondanza delle sue strutture dati rendono molto più problematica la recovery di eventuali errori.
Il filesystem ext2 è suddiviso logicamente in più parti, dette cylinder groups, che vengono gestite come entità separate ed autonome pur facendo parte dello stesso fs. Lo scopo di questa suddivisione è duplice. Per prima cosa si vogliono minimizzare le conseguenze di eventuali errori, cioè fare sì che se alcuni dati di un cylinder group risultano corrotti il danno resti limitato all'interno del cylinder group stesso e non si propaghi a tutto il fs. Il concetto è un po' analogo a quallo dei compartimenti stagni dei sommergibili, se uno si buca il sommergibile non affonda. Il secondo motivo è invece la tendenza a localizzare i files nell'intorno delle loro directory per ridurre i tempi di accesso, cosa che viene ottenuta cercando di allocare inodes e blocchi nello stesso cylinder group delle directory. Per ridurre ultriormente le possibilità che un intero filesystem venga corrotto a causa di eventuali errori, sia il super_block che le group descriptor tables vengono duplicati in ogni cylinder group, come mostrato in figura:

In questo modo se uno dei super_block o group descriptor viene corrotto a causa di qualche errore esso può essere facilmente ripristinato a partire da una delle sue copie. Abbiamo quindi una struttura altamente ridondante che permette la recovery di eventuali errori.
Lo spazio all'interno del fs è gestito separatamente ed autonomamente per ciascun cylinder-group. Come si vede dalla figura ciascun cylinder group contiene una block bitmap, che indica quali blocchi del cylinder group sono stati allocati a files o directories, una inode bitmap, che indica analogamente quali inode risultano allocati, ed una inode table che contiene gli inodes appartenenti al cylinder group. Ciascuna bitmap è organizzata come una sequenza di bits ognuno dei quali indica se il corrispondente inode o blocco è libero o occupato. Ciascuna bitmap occupa esattamente un blocco e quindi il numero massimo di inodes o di blocchi che possono essere contenuti in un cylinder group è data dalla dimensione in bytes di un blocco moltiplicata per 8, per esempio in un fs con blocchi da 1K ci sono 8192 (1024 * 8) blocchi per cylinder group, poiché la block bitmap può contenere al massimo 8192 bits.
Dato che i blocchi e gli inodes sono ripartiti nei vari cylinder group, per individuare la posizione di uno di essi all'interno del fs a partire dal suo numero occorre prima individuare il cylinder group, dividendo il numero per il numero di oggetti per cylinder group e quindi individuare l'oggetto all'interno del cylinder group utilizzando come indice il resto di tale divisione. Per esempio volendo accedere all'inode 17654 di un fs con 1016 inodes per group si ottiene:
group = 17654 / 1016 = 17 index = 17654 % 1016 = 382e quindi si deve cercare l'inode 382 del cylinder group 17. Ciascun gruppo contiene solo una parte degli inodes e dei blocchi di tutto il fs e l'indice ottenuto vale solo all'interno del gruppo. Dal punto di vista dell'utente il filesystem è visto come un tutt'uno e la sua suddivisione in cylinder-groups è totalmente trasparente.
Ciascun cylinder-group è descritto da un apposito blocco di controllo detto group descriptor, che ha la seguente struttura:
struct ext2_group_desc {
__u32 bg_block_bitmap; /* Blocks bitmap block */
__u32 bg_inode_bitmap; /* Inodes bitmap block */
__u32 bg_inode_table; /* Inodes table block */
__u16 bg_free_blocks_count; /* Free blocks count */
__u16 bg_free_inodes_count; /* Free inodes count */
__u16 bg_used_dirs_count; /* Directories count */
__u16 bg_pad;
__u32 bg_reserved[3];
};
Il group descriptor contiene, oltre ai puntatori alle bitmap di allocazione ed alla tabella degli inodes, anche dei contatori (bg_free_blocks_count, bg_free_inodes_count e bg_used_dirs_count) che sono aggiornati ed utilizzati dalle routines di allocazione del fs. In particolare bg_used_dirs_count viene utilizzato durante la creazione di una nuova directory per ripartire uniformemente le directory fra i vari gruppi, in modo che possa essere applicato il principio della località dei dati, cioè che in ciascun gruppo ci possa essere spazio per allocare gli inodes ed i blocchi dei files contenuti nelle directories del gruppo. Ovviamente se ciò non è possibile inodes e blocchi vengono allocati anche in altri gruppi dove c'è dello spazio disponibile. La località dei dati è fondamentale per ottenere buone prestazioni dal fs stesso. Per esempio quando si fa un ls -l è necessario per ogni entry della directory che si sta listando accedere anche all'inode corrispondente ed è quindi molto importante che esso sia nelle immediate vicinanze della directory stessa per poter ridurre i tempi di accesso al disco. Lo stesso principio vale ovviamente quando si vuole leggere i blocchi di dati di un file contenuto in una certa directory.
L'inode è la risorsa principale di un filesystem unix. Ad ogni file o directory è associato univocamente un inode che ne identifica le caratteristiche ed indica dove sono fisicamente memorizzati i dati. Tutte le operazioni su un file o una directory vengono effettuate tramite il suo inode, che contiene tutte le informazioni sul file stesso, esclusi i dati veri e propri, come sintetizzato dalla seguente figura:
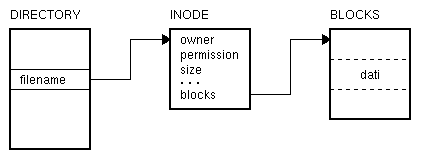
Gli inodes sono numerati progressivamente da 1 in su ed il loro numero è l'informazione utilizzata dal kernel per accedere all'inode e quindi ai dati del file corrispondente. La struttura di un inode di un fs ext2 è la seguente:
struct ext2_inode {
__u16 i_mode; /* File mode */
__u16 i_uid; /* Owner Uid */
__u32 i_size; /* Size in bytes */
__u32 i_atime; /* Access time */
__u32 i_ctime; /* Creation time */
__u32 i_mtime; /* Modification time */
__u32 i_dtime; /* Deletion Time */
__u16 i_gid; /* Group Id */
__u16 i_links_count; /* Links count */
__u32 i_blocks; /* Blocks count */
__u32 i_flags; /* File flags */
union {
struct {
__u32 l_i_reserved1;
} linux1;
struct {
__u32 h_i_translator;
} hurd1;
struct {
__u32 m_i_reserved1;
} masix1;
} osd1; /* OS dependent 1 */
__u32 i_block[EXT2_N_BLOCKS];/* Pointers to blocks */
__u32 i_version; /* File version (for NFS) */
__u32 i_file_acl; /* File ACL */
__u32 i_dir_acl; /* Directory ACL */
__u32 i_faddr; /* Fragment address */
union {
struct {
__u8 l_i_frag; /* Fragment number */
__u8 l_i_fsize; /* Fragment size */
__u16 i_pad1;
__u32 l_i_reserved2[2];
} linux2;
struct {
__u8 h_i_frag; /* Fragment number */
__u8 h_i_fsize; /* Fragment size */
__u16 h_i_mode_high;
__u16 h_i_uid_high;
__u16 h_i_gid_high;
__u32 h_i_author;
} hurd2;
struct {
__u8 m_i_frag; /* Fragment number */
__u8 m_i_fsize; /* Fragment size */
__u16 m_pad1;
__u32 m_i_reserved2[2];
} masix2;
} osd2; /* OS dependent 2 */
};
Come si vede ci sono molte informazioni che descrivono le caratteristiche
di un file, alcune delle quali relative a funzionalità previste ma
al
momento non ancora utilizzate, per esempio acl e fragment.
Il primo campo, i_mode contiene le permissions ed il tipo di file ed è suddiviso nel seguente modo:
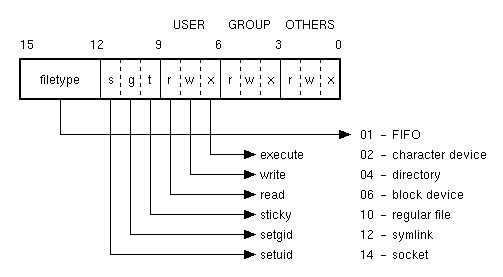
Il campo i_size contiene la dimensione in bytes del file oppure, nel caso si tratti di un device, un numero di 16 bit che specifica il major e il minor number del device stesso. Per esempio le partizioni del primo harddisk ide hanno major number 3 e minor number che va da 1 a 9:
$ ls -l /dev/hda[1-9] brw-rw---- 1 root disk 3, 1 Apr 28 1995 /dev/hda1 brw-rw---- 1 root disk 3, 2 Apr 28 1995 /dev/hda2 brw-rw---- 1 root disk 3, 3 Apr 28 1995 /dev/hda3 brw-rw---- 1 root disk 3, 4 Apr 28 1995 /dev/hda4 brw-rw---- 1 root disk 3, 5 Apr 28 1995 /dev/hda5 brw-rw---- 1 root disk 3, 6 Apr 28 1995 /dev/hda6 brw-rw---- 1 root disk 3, 7 Apr 28 1995 /dev/hda7 brw-rw---- 1 root disk 3, 8 Apr 28 1995 /dev/hda8 brw-rw---- 1 root disk 3, 9 Apr 28 1995 /dev/hda9Quando si accede ad un device, sempre tramite il suo inode, il major e minor number vengono utilizzati dal kernel per sapere che classe di device e quale particolare dispositivo all'interno di quella classe si sta utilizzando, in modo da individuare il particolare driver all'interno del kernel in grado di accedere fisicamente allo specifico hardware. Per esempio il file /dev/tty2, con major e minor 4,2 è contenuto in un fs nell'harddisk, ma essendo un character device i suoi dati non vengono letti dall'harddisk ma dal device numero 2 (tty2) del driver numero 4 (ttyp), cioè dalla console numero 2 del nostro pc.
I quattro campi i_atime, i_ctime, i_mtime, e i_dtime contengono rispettivamente i tempi di ultimo accesso, creazione, modifica e cancellazione del file, espressi in secondi dall'1-1-1970 secondo lo standard unix.
Il campo i_links_count contiene il numero di hard-links che puntano all'inode. Il suo valore è di solito 1, ma può essere maggiore di 1 se vengono creati degli ulteriori hard-links all'inode.
Il campo i_blocks indica il numero di blocchi occupati dal file, compresi anche i blocchi di indirizzamento indiretto che verranno illustrati più avanti. E' da notare che i campi i_size ed i_blocks possono indicare dimensioni del file differenti, dato che in unix è possibile creare i cosiddetti sparse files cioè dei files in cui non tutti i blocchi necessari a raggiungere la dimensione specificata risultano allocati, in altre parole dei files coi buchi. Nella figura seguente è illustrato un file sparso di 7000 bytes che però occupa solo 3 blocchi da 1024 bytes. Il file ha allocati solo i blocchi di dati corrispondenti agli offset 0, 2048 e 6144, e quindi una lettura fatta dopo una seek ad una posizione non allocata ritorna semplicemente degli zeri. Il vantaggio è che pur avendo un file che nominalmente è di 7000 bytes posso allocare solo i 3KB corrispondenti alle posizioni in cui ho dati significativi:

$ ls -ls pippo pluto 3 -rw-r--r-- 1 dz users 2500 Apr 23 13:55 pippo 0 lrwxrwxrwx 1 dz users 5 Apr 23 13:55 pluto -> pippo
Il campo i_flags contiene dei flags aggiuntivi che indicano particolari caratteristiche del file:

I campi i_file_acl e i_dir_acl non sono attualmente usati ma sono previsti per implementare il controllo sull'accesso al file tramite Access Control List (ACL).
Anche i campi l_faddr, l_i_frag e l_i_fsize non sono usati attualmente, ma sono comunque presenti nell'inode per poter permettere in futuro di implementare la gestione dei frammenti di blocchi, consentendo così di ottimizzare l'occupazione di spazio su disco delle code dei files, che attualmente occupano un intero blocco anche se devono contenere solo pochi bytes.
Nell'inode troviamo anche un array i_blocks di 15 elementi che contiene i puntatori ai blocchi di dati del file. I primi 12 elementi, da i_blocks[0] a i_blocks[11], sono detti direct blocks e contengono i numeri dei primi 12 blocchi del file. L'elemento successivo, i_blocks[12], punta invece ad un blocco, detto indirect block, che non contiene dati del file ma un array di puntatori ai blocchi di dati. Assumendo che ciascun blocco abbia dimensione pari a 1024 bytes esso potrà contenere 256 (1024 / 4) puntatori a blocchi di dati ed sarà pertanto in grado di indirizzare i blocchi da 12 a 268. L'elemento i_blocks[14] punta ad un altro blocco, detto double indirect block, che punta ad un blocco di puntatori a blocchi di puntatori, in grado quindi di indirizzano i 256 * 256 blocchi di dati che vanno da 269 a 65804. Troviamo infine i_blocks[15], detto triple indirect block, che aggiunge un ulteriore livello di indirezione consentendo l'indirizzamento di altri 256 * 256 * 256 blocchi di dati oltre il 65804. Ovviamente tutti questi blocchi indiretti vengono allocati solo se sono effettivamente necessari per indirizzare dei blocchi di dati. Il tutto può essere rappresentato graficamente così:

Il vantaggio di questa struttura è che per files piccoli non devo allocare spazio aggiuntivo per contenere i puntatori ai dati, dato che per i primi 12K sono sufficienti i puntatori diretti contenuti nell'inode. In questo modo si risparmia anche l'accesso al disco che sarebbe necessario per leggere tale blocco. Man mano che il file cresce di dimensioni è invece necessario introdurre livelli successivi di indirizzamento indiretto per contenere i puntatori ai dati. Confrontando questa organizzazione con quella del dos si può notare che distribuendo i puntatori ai dati nelle vicinanze dei dati stessi si migliorano i tempi di accesso, mentre in dos è sempre necessario muovere le testine del disco all'inizio della partizione per poter leggere i puntatori ai cluster contenuti nella FAT.
Una cosa importante da notare è che l'allocazione dello spazio per i dati non è fatta "come capita", come succede con dos e windows, ma secondo un algoritmo che cerca di utilizzare blocchi contigui minimizzando così la frammentazione dei dati che è invece tipica dei sistemi operativi più primitivi. Questo è possibile perch´ ext2 utilizza dei contatori che indicano in ogni istante quanto spazio libero c'è per ogni cylinder-group e delle bitmap di allocazione che permettono di cercare velocemente dove conviene allocare nuovo spazio per i dati. Contatori analoghi vengono mantenuti per inodes e directories in modo da poter distribuire i dati uniformemente per tutto il filesystem.
Di tutti gli inodes che vengono creati in un filesystem quando viene formattato alcuni sono riservati e non possono essere allocati a files degli utenti. Gli inodes riservati dell'ext2 sono i seguenti:
| 1 | bad blocks inode Contiene la lista dei settori difettosi della partizione che ospita il fs e che pertanto non devono essere usati. | |
| 2 | root inode È l'inode della directory root del filesystem, quella che col mount viene collegata al mount-point. | |
| 3 | acl index inode Attualmente non usato, verrà utilizzato in futuro per implementare le ACL. | |
| 4 | acl data inode Attualmente non usato, verrà utilizzato in futuro per implementare le ACL. | |
| 5 | boot loader inode Può contenere un breve programma in codice macchina in grado di caricare un sistema operativo. | |
| 6 | undelete directory inode Attualmente non usato, verrà utilizzato in futuro per implementare la funzionalità di undelete dei files. | |
| 7-10 | Attualmente non usati, sono riservati per estensioni future del fs. |
Come già visto una directory è un file come tutti gli altri, con l'unica differenza che i dati in esso contenuti sono le informazioni sui files nella directory, e viene pertanto gestito in modo particolare dal filesystem e dal kernel. Ciascuna entry di directory è costituita da un record di lunghezza variabile allineata alla word (4 bytes) contente solamente il nome del file ed il numero di inode corrispondente. Tutte le altre informazioni sul file non hanno niente a che fare con la directory in cui esso è contenuto e sono pertanto memorizzate nel suo inode. La directory serve solo a collegare il nome del file col suo inode. La directory entry di ext2 è descritta dalla seguente struttura:
#define EXT2_NAME_LEN 255
struct ext2_dir_entry {
__u32 inode; /* Inode number */
__u16 rec_len; /* Directory entry length */
__u16 name_len; /* Name length */
char name[EXT2_NAME_LEN]; /* File name */
};
Il tutto si può anche rappresentare graficamente così:

Se esaminiamo invece una entry di una directory msdos possiamo vedere che essa è di lunghezza fissa e contiene al suo interno anche tutte quelle informazioni (poche per la verità) che in unix si è invece preferito memorizzare separatamente nell'inode. Si può vedere che il dos gestisce solo la data e ora di ultima modifica, che mancano totalmente i concetti di utente e di permessi di accesso, e che ovviamente il nome del file è di soli 8+3 caratteri, ovviamente tutti rigorosamente maiuscoli:
struct msdos_dir_entry {
__s8 name[8],ext[3]; /* name and extension */
__u8 attr; /* attribute bits */
__u8 unused[10];
__u16 time,date,start;/* time, date and first cluster */
__u32 size; /* file size (in bytes) */
};
Non vi descrivo come sono implementati i nomi lunghi nel filesystem di tipo
vfat utlizzato da Windows95 perché ne sareste assolutamente
inorriditi.
Vi basti sapere che il vfat non è altro che un normale msdos un po'
accrocchiato per farlo sembrare una novità. In effetti sul vfat ci
gira tranquillamente anche il vecchio dos, quindi tanto nuovo non
può essere.
Come tutti sanno in unix è possibile creare dei link simbolici ad un file, cioè utilizzare un file con un certo path per fare in realtà riferimento ad un file che sta da un'altra parte, al limite su un altro disco o su un altro computer. Esisono anche i link fisici ma questi non sono altro che diverse entry di directory che puntano allo stesso inode. Un link simbolico a un file è di solito implementato memorizzando il pathname del file destinazione in un blocco di dati associato all'inode del link stesso.
Nel filesystem ext2 in realtà non è sempre così poiché se il pathname destinazione è lungo non più di 59 bytes esso viene memorizzato direttamente nell'array i_blocks al posto dei puntatori ai blocchi di dati. Così facendo si risparmiano l'allocazione al blocco di dati e l'accesso al disco necessario per leggere il pathname del target, dato che questo è già disponibile nell'inode. I symlinks di questo tipo sono per questo motivo chiamati Fast Symbolic Link e ciascuno di essi occupa un inode ma nessun blocco di dati. Se invece il pathname del target è più lungo di 60 bytes deve essere allocato un blocco di dati come per un file normale. Nella figura seguente sono rappresentati i due tipi di symlink:
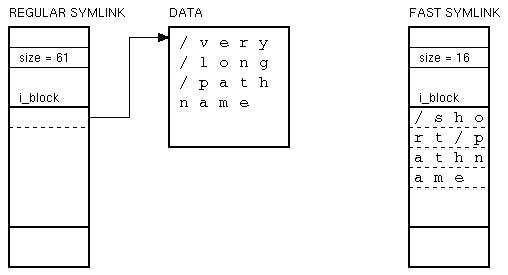
Di fatto quasi tutti i link simbolici presenti in un filesystem ext2 sono dei Fast Symlink, dato che nella realtà non si usano mai pathnames lunghi più di 59 caratteri.
Si può anche vedere che esiste in teoria una ulteriore possibilità di ottimizzazione del fs ext2 che consisterebbe nell'implementazione dei cosiddetti Fast Files, cioè di quei files di lunghezza minore o uguale di 59 bytes il cui contenuto potrebbe essere memorizzato direttamente nell'inode al posto dei puntatori ai blocchi, analogamente a quanto avviene per i Fast Symlink. Al momento questo non è implementato ma in teoria si potrebbe fare. Poiché il numero di inodes di un filesystem è sempre molto sovradimensionato rispetto alla quantità effettivamente necessaria si può concludere che creare un Fast Symlink (o un ipotetico Fast File) costa molto poco in termini di spazio occupato su disco dato che l'unico spazio allocato è quello occupato dalla entry di directory.
|
|
<- Linux - Copertina - XFSTT -> |
|